ArXiv
Preprint
Source
Code
Github
Fine-Tuned
Model Weights
How Does Fine-Tuning Improve Language Models' Capabilities?
Fine-tuning has become a ubiquitous technique for enhancing language models' capabilities across diverse tasks. However, the mechanistic updates underpinning these performance gains remain poorly understood. Does the fine-tuned model employ the same mechanism, or does it modify its algorithm to address a task? Are the same set of model components (i.e. circuit) engaged in performing the task, or are different ones involved?
Our findings suggest that fine-tuning enhances, rather than fundamentally alters, the mechanistic operation of the model. Specifically, we observed that the task of entity tracking in Llama-7B and its fine-tuned variants is primarily performed by the same circuit. Not only are the same set of components involved, but their functionality also remains consistent across the models. Finally, we were able to attribute the performance gap to an improved sub-mechansim in the fine-tuned models.
Is the Same Circuit Present After Fine-Tuning?
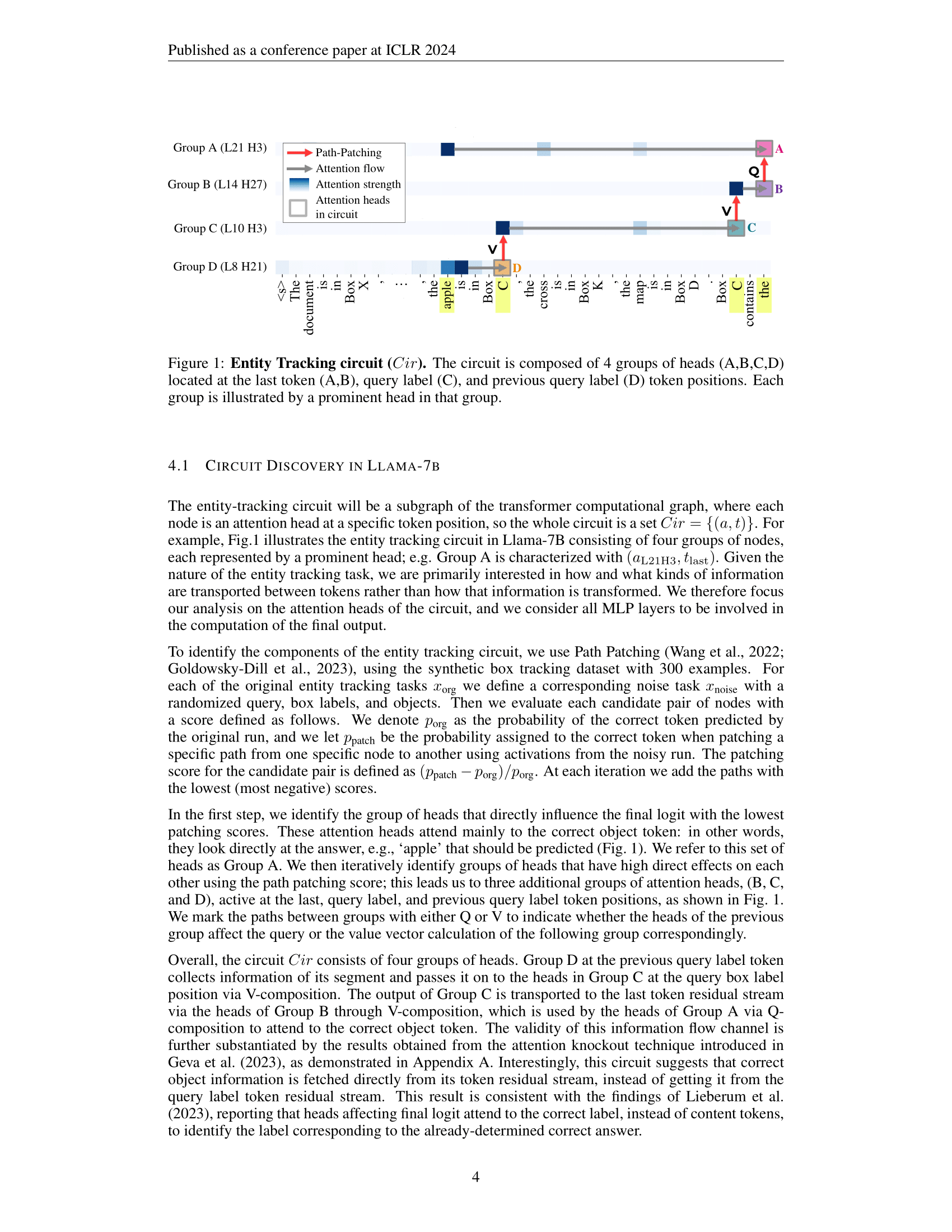
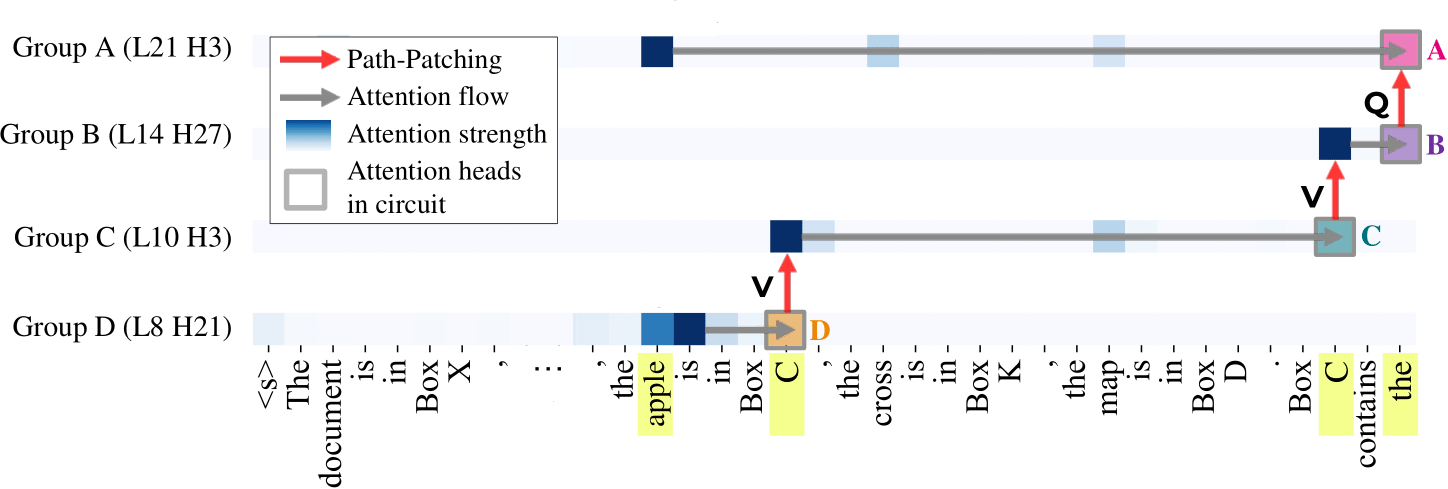
We employ Path Patching to identify the circuit for entity tracking in Llama-7B, comprising four head groups, as shown in Figure 1. Group D collects segment information at previous query label token and passes it to Group C via V-composition. The output of Group C is then conveyed to the last token residual stream through V-composition with Group B, and utilized by Group A heads via Q-composition to attend to the correct object token.
Surprisingly, we found that the same circuit is primarily responsible for performing entity tracking in both the base and fine-tuned models. Specifically, Vicuna-7B utilizes roughly the same circuit as that of Llama-7B to perform entity tracking. Whereas, in Goat-7B and FLoat-7B, the same circuit is present, but with additional components.
| Accuracy | |||||
|---|---|---|---|---|---|
| Model | Finetuned? | Full-Model | Circuit | Random Circuit | Faithfulness |
| Llama-7B | -- | 0.66 | 0.66 | 0.00 | 1.00 |
| Vicuna-7B | User conversations | 0.67 | 0.65 | 0.00 | 0.97 |
| Goat-7B | Arithmetic tasks (LoRA) | 0.82 | 0.73 | 0.01 | 0.89 |
| FLoat-7B | Arithmetic tasks (w/o LoRA) | 0.82 | 0.72 | 0.01 | 0.88 |
Is Circuit Functionality the Same After Fine-Tuning?
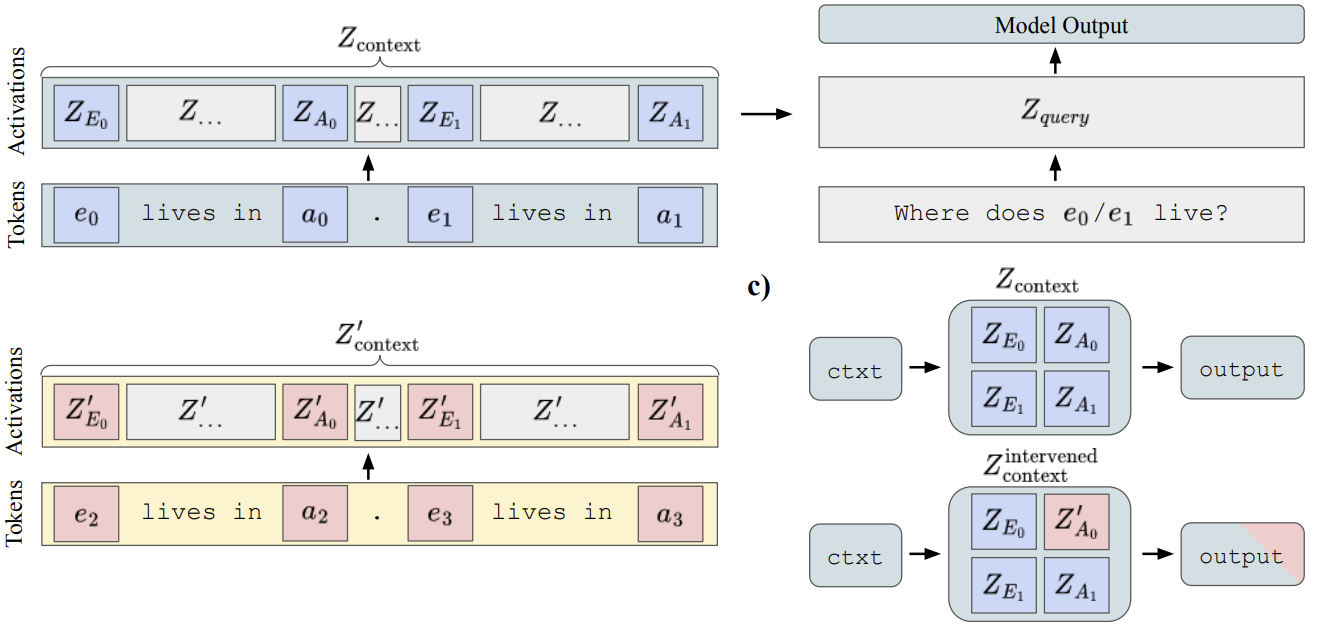
We employ Desiderata-based Component Masking (DCM) to discern the functionality of circuit components. For more details on the method, please refer to dcm.baulab.info.
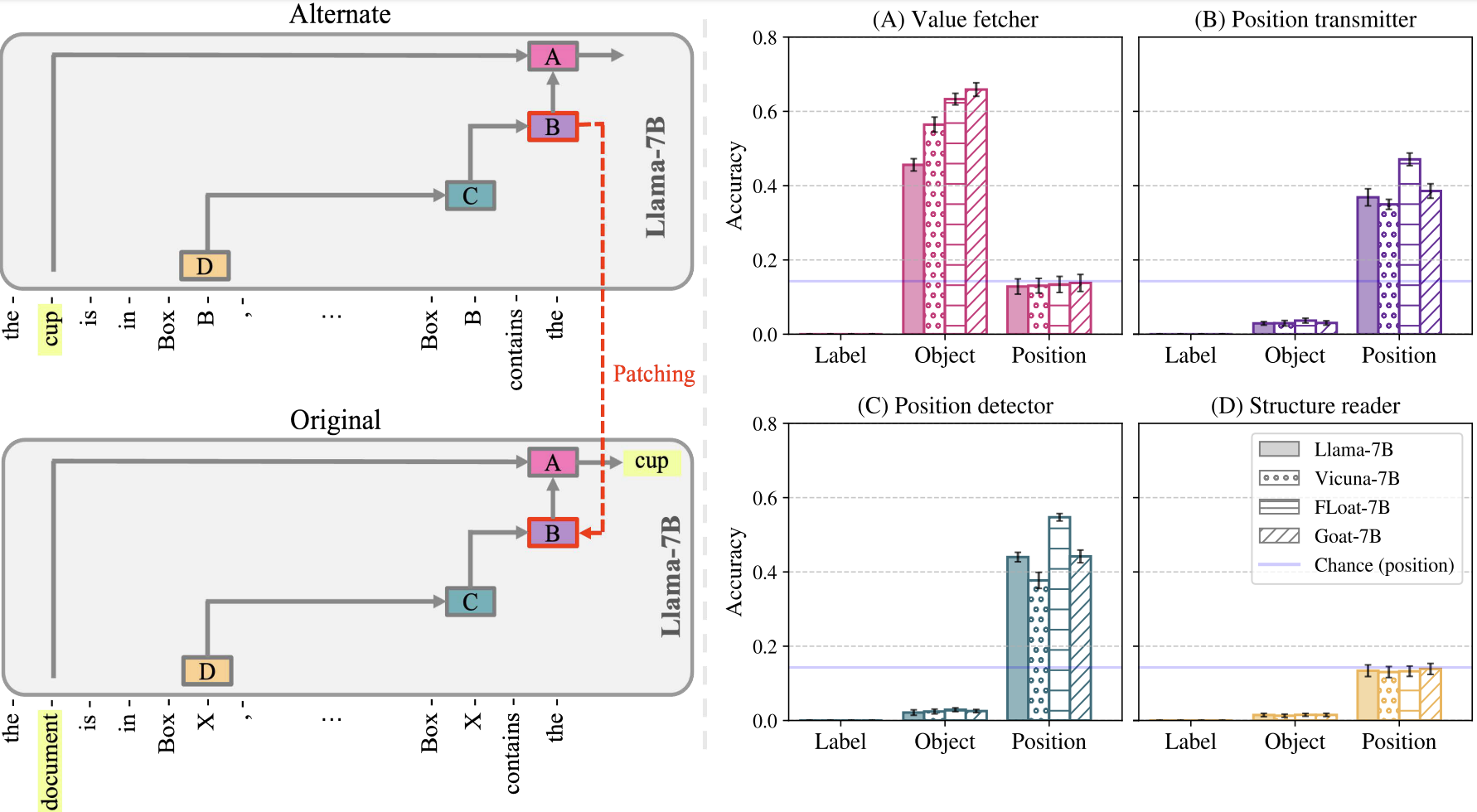
We discovered that the functionality of the circuit components remains consistent across the models. Specifically, Group A primarily encodes the value of the correct object, while Groups B and C are responsible for encoding positional information. Additionally, we observed that Group D is insensitive to each of the three functionalities.
The observations that the same circuit is primarily responsible for performing entity tracking in both the base and fine-tuned models, and that the functionality of the circuit components remains consistent across the models, indicates that the fine-tuned models leverage the same mechanism as the base model to perform entity tracking. However, increased performance of fine-tuned models suggest that fine-tuning enhances that existing mechanism.
Why Do Goat-7B and FLoat-7B Perform Better?
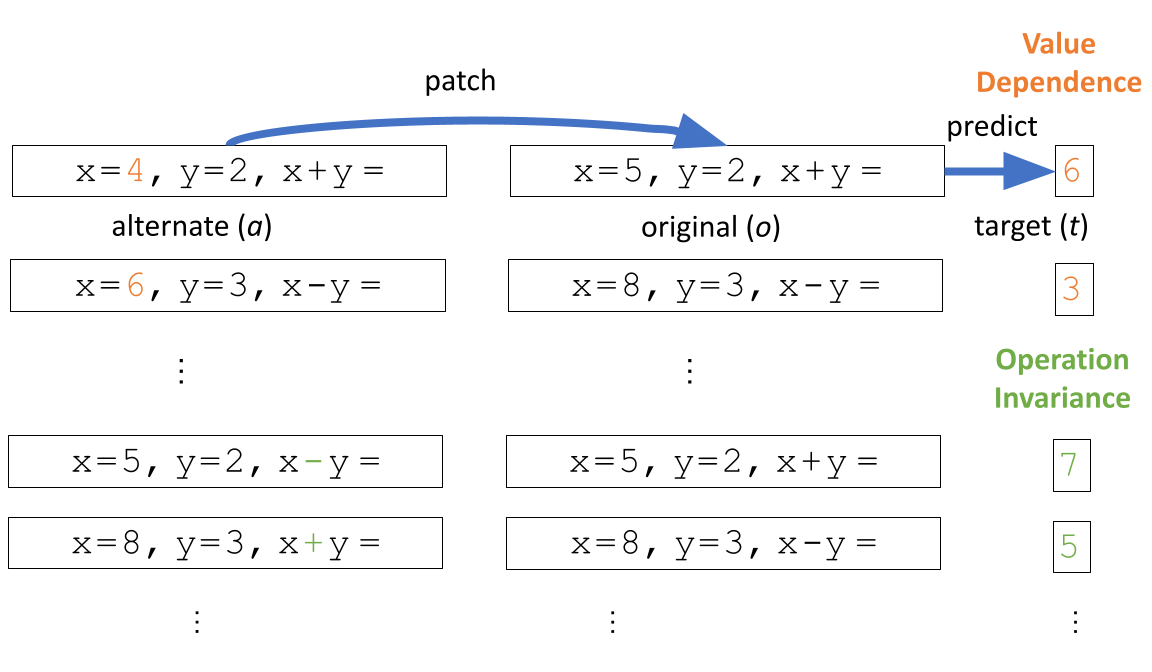
To attribute the performance gap between fine-tuned models and Llama-7B to a specific sub-mechanism, we propose a novel method Cross-Model Activation Patching (CMAP). Unlike naive activation patching which involves patching activations of the same model on different inputs, CMAP requires patching activations of the same components of different models on the same input. More specifically, we patch the output of heads in Goat-7B circuit from the Goat-7B model to Llama-7B model, to identify which step in Goat-7B model has improved compared to Llama-7B. Similarly, we perform the same patching process for heads in the FLoat-7B circuit.
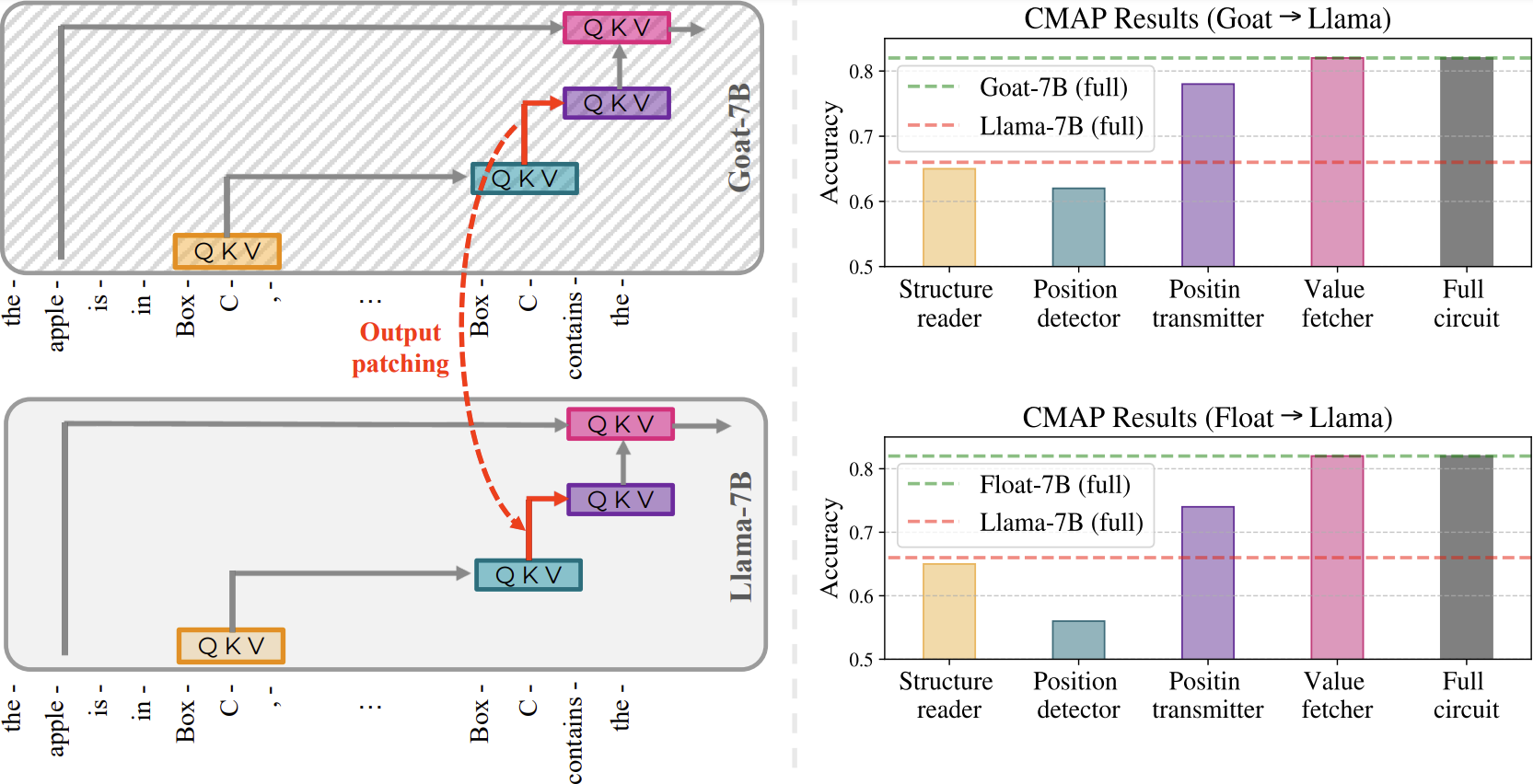
We note that the activations of fine-tuned models are compatible with those of the base model, despite the possibility of using entirely different subspaces and/or norms to encode information. Furthermore, our findings indicate that the Value Fetcher Heads in fine-tuned models encode an improved representation of the correct object, consistent with the results from the previous experiment. Additionally, we observe that the Position Transmitter Heads transmit augmented positional information to the Value Fetcher Heads.
Related Works
Our work builds upon insights from previous research that has investigated large language models from various other perspectives:
Entity Tracking
![]() Najoung Kim, Sebastian Schuster. Entity Tracking in Language Models. ACL 2023.
Najoung Kim, Sebastian Schuster. Entity Tracking in Language Models. ACL 2023.
Notes: Investigated whether large language models can track the states of entities through a discourse,
and
finds that models trained on both text and code exhibit better entity tracking abilities than models trained
solely on text.
 Belinda Z. Li, Maxwell Nye, Jacob Andreas. Implicit Representations of Meaning in Neural Language Models.
ACL - IJCNLP 2021.
Belinda Z. Li, Maxwell Nye, Jacob Andreas. Implicit Representations of Meaning in Neural Language Models.
ACL - IJCNLP 2021.
Notes: Investigated whether neural language models implicitly encode representations of meaning without
being explicitly trained to do so.
Transformer Interpretability
 Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, Jacob Steinhardt. Interpretability in the
Wild: a Circuit for Indirect Object Identification in GPT-2 small. ICLR 2023.
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, Jacob Steinhardt. Interpretability in the
Wild: a Circuit for Indirect Object Identification in GPT-2 small. ICLR 2023.
Notes: Proposed Path Patching algorithm to reverse engineer the circuit responsible for performing
Indirect Object Identification (IOI) task in a GPT2-small.
 Xander Davies, Max Nadeau, Nikhil Prakash, Tamar Rott Shaham, David Bau. Discovering Variable Binding
Circuitry with Desiderata. Workshop on Challenges in Deployable Generative AI at International Conference on
Machine Learning (ICML 2023).
Xander Davies, Max Nadeau, Nikhil Prakash, Tamar Rott Shaham, David Bau. Discovering Variable Binding
Circuitry with Desiderata. Workshop on Challenges in Deployable Generative AI at International Conference on
Machine Learning (ICML 2023).
Notes: Proposed Desiderata-based Component Masking (DCM) method to localize components responsible for
variable binding in Llama-13B.
 Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao
Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez,
Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan,
Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao
Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez,
Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan,
Sam McCandlish, Chris Olah. A Mathematical Framework for Transformer Circuits. Anthropic 2021.
Notes: Analyzes internal mechanisms of transformer components, developing mathematical tools for
understanding patterns of computations. Observes information-copying behavior in self-attention and implicates
it in the strong performance of transformers.
Complimentary Works
 Samyak Jain, Robert Kirk, Ekdeep Singh Lubana, Robert P. Dick, Hidenori Tanaka, Edward Grefenstette, Tim
Rocktäschel, David Scott Krueger. Mechanistically analyzing the effects of fine-tuning on procedurally
defined tasks. arXiv preprint (2023).
Samyak Jain, Robert Kirk, Ekdeep Singh Lubana, Robert P. Dick, Hidenori Tanaka, Edward Grefenstette, Tim
Rocktäschel, David Scott Krueger. Mechanistically analyzing the effects of fine-tuning on procedurally
defined tasks. arXiv preprint (2023).
Notes: Investigated the impact of fine-tuning on LLMs from a mechanistic perspective. Although their
main
finding, suggesting that fine-tuning minimally alters pretrained capabilities, resonates with our result
of enhancing existing mechanisms through fine-tuning, their study involved controlled experiments
utilizing transformer models created using the tracr library. In contrast, our
experiments focus on established LLMs such as Llama-7B and their fine-tuned variants, specifically
in the context of entity tracking tasks, which we believe better represent real-world language tasks.
 Jiahai Feng, Jacob Steinhardt. How do Language Models Bind Entities in Context? arXiv preprint (2023).
Jiahai Feng, Jacob Steinhardt. How do Language Models Bind Entities in Context? arXiv preprint (2023).
Notes: Investigated how LLMs keep track of various properties associated with an entity. Their findings
indicated that models generate binding ID vectors corresponding to entities and attributes. We find it
intriguing to further investigate the interaction between these binding ID vectors and the entity tracking
circuit we have identified.
How to cite
This work appeared at ICLR 2024. It can be cited as follows.
bibliography
Nikhil Prakash, Tamar Rott Shaham, Tal Haklay, Yonatan Belinkov, and David Bau.
"Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking." Proceedings of the
2024 International Conference on Learning Representations (ICLR 2024).
bibtex
@inproceedings{prakash2023fine,
title={Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking},
author={Prakash, Nikhil and Shaham, Tamar Rott and Haklay, Tal and Belinkov, Yonatan and Bau, David},
booktitle={Proceedings of the 2024 International Conference on Learning Representations},
note={arXiv:2402.14811},
year={2024}
}